「AIテキストマイニング」を使ってテキストマイニングしよう

テキストマイニングツールを使って文章などのテキストデータをマイニングすることができます。
膨大なテキストデータの中から有益な情報を抽出するのは大変な作業です。
テキストマイニングツールを使うことで膨大なテキストデータの中から有益な情報を簡単に抽出することができます。
このテキストマイニングツールのひとつとして、「AIテキストマイニング」があります。AIテキストマイニングはWEBマイニングツールとも呼ばれる、クラウド型のマイニングツールです。
WEBサイト上にテキストデータを入力することで、ワードクラウドや単語出現頻度などのマイニング結果を出力してくれます。
このAIテキストマイニングを使ってどのように情報が抽出されているのか、ツールの使い方を簡単にご紹介したいと思います。
「AIテキストマイニング」の機能
解析したいテキストを入力
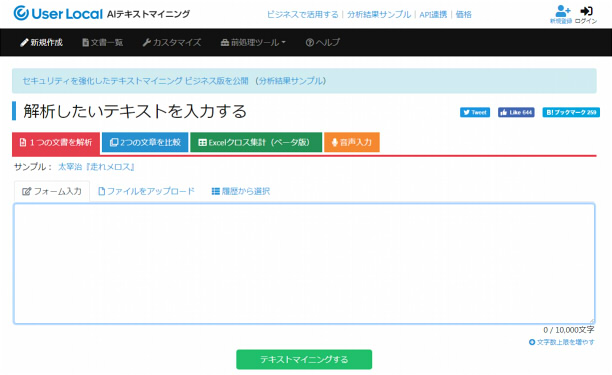
テキストマイニングを行う対象のテキストデータをAIテキストマイニングのボックス内に入力します。
そして、下の「テキストマイニングする」のボタンを押せば、マイニングを実行します。
AIテキストマイニングは比較的簡単に利用できるテキストマイニングツールで、他のテキストマイニングツールは初期設定が複雑で初めてテキストマイニングツールを使う人には設定に時間を取られる場合があります。
AIテキストマイニングは初期設定などの複雑な操作を行わずに、データの分析を行えます。
今回は、サンプルとして用意されている「走れメロス」のテキストデータから分析結果を見ていきましょう。
ワードクラウド
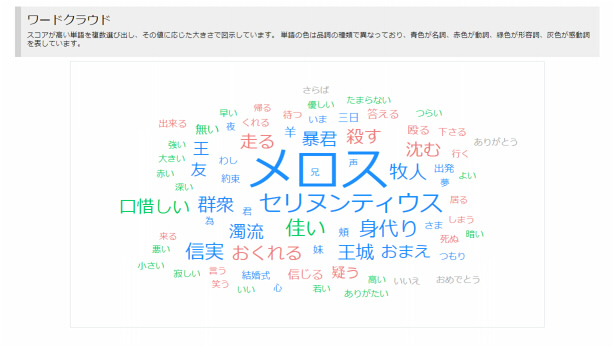
ワードクラウドという方法で、テキストデータの中から出現頻度の高い単語(ワード)を頻度に応じてフォントの色や大きさを変えて図に表示する方法のことです。
ワードクラウドはブログ機能に実装されていることが多く、ブログ内でユーザーがどんなワードに興味を持っているか、訪問者データを分析する際に使われます。
テキストマイニングでは、重要度の高い単語を抽出して表示されます。
単語出現頻度
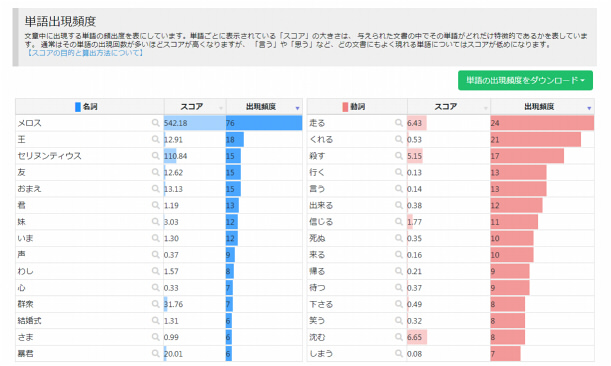
単語出現頻度は、テキストデータの中に出現する単語を出現頻度ごとに図で表した物です。
テキストデータの中で使われている単語の使用頻度を調べるのに使える他、テキストマイニングツールでは、スコアといった値を使い、単語の重要度を図に表示させています。
このスコアは、tf-idfなどの情報検索のロジックを用いて行われており、各テキストマイニングツールがどのようなロジックで単語のスコアを表示させるかあらかじめ確認しておく必要があります。
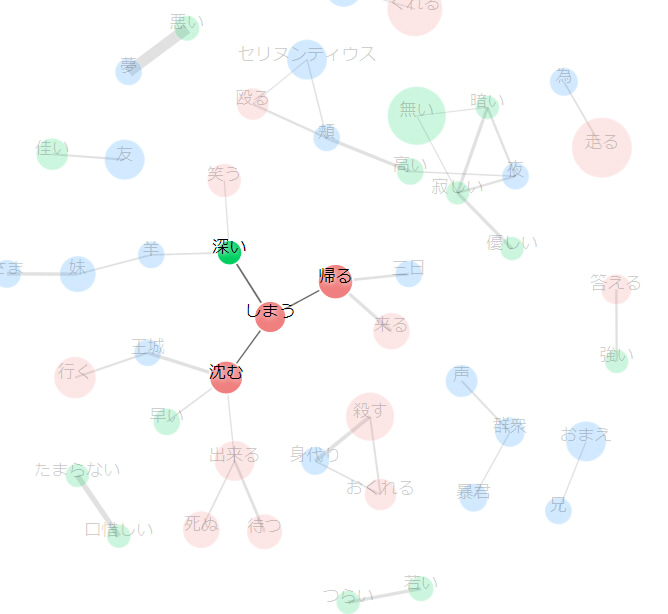
共起キーワード
共起ワードとは、テキストデータ内の一文にセットで出現する頻度が高い単語を図に表したものです。
例えば、「東京の観光スポットとしてスカイツリーがある」、「スカイツリーは東京の新しい名所です」という一文があった場合、「東京」と「スカイツリー」が一文の中で同時に出現しているので共起ワードということになります。
図の中の共起ワードにカーソルをあわせると、その共起ワードにフォーカスすることができます。
2次元マップ
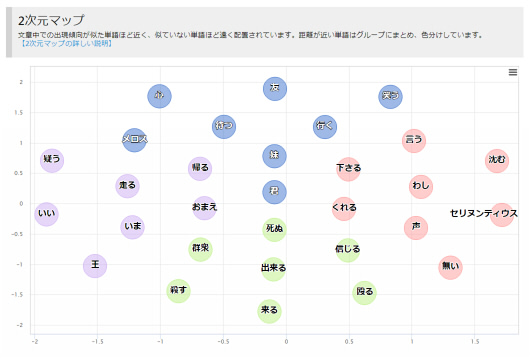
2次元マップでは、テキストデータ内で出現する単語で、近くに出現する単語同士は同じ場所に出現する傾向を分析して図に表したものです。
図に表示される単語で、近くにある単語同士は同時に出現する頻度の高い単語で、単語同士が離れている場合は同時に出現する頻度の少ない単語となっています。
係り受け解析
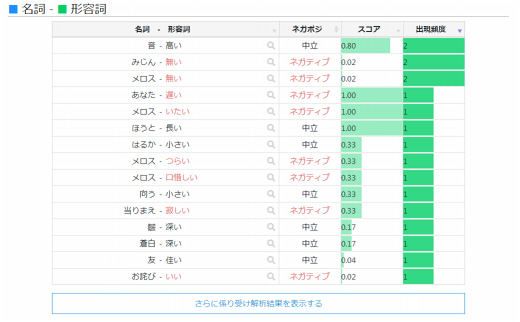
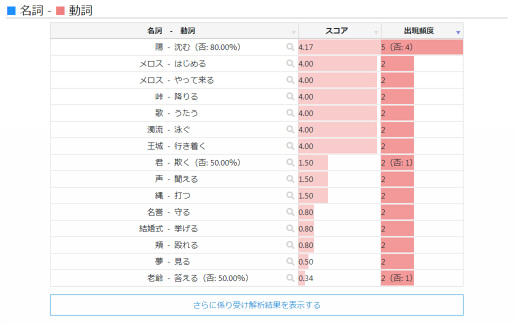
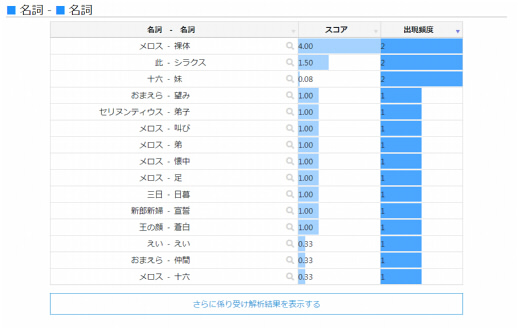
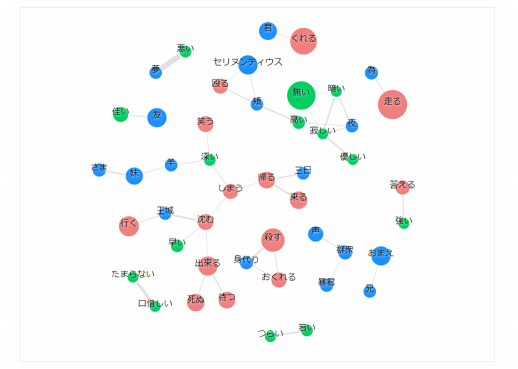
係り受け解析では、テキストデータ内に出現する名詞に対して係る形容詞や動詞を図で表示します。
図では、スコアと出現頻度が一緒に表示されており、名詞に係る形容詞や動詞の割合を確かめることができます。
階層的クラスタリング
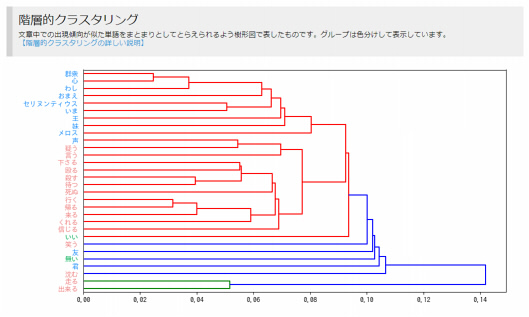
階層的クラスタリングとは、テキストデータ内で出現する単語で、出現頻度が似ている単語をグループ毎にまとめて図に表示したものです。
図の中では、似たグループの単語が近く表示され、出現頻度の似通っていない単語は単語に表示されます。